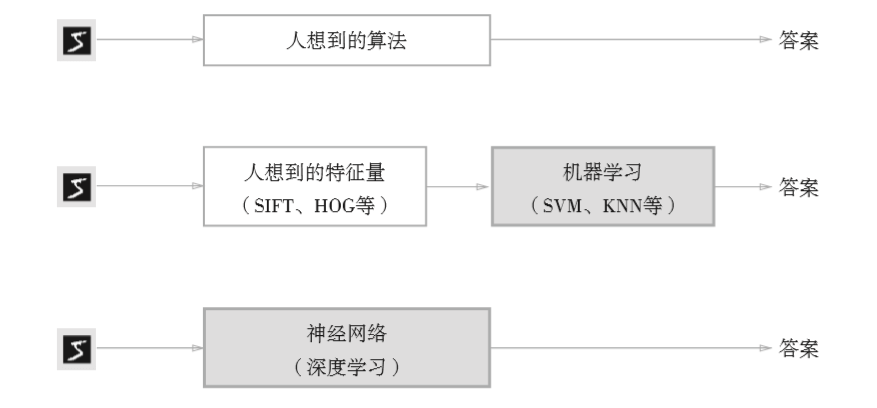
数据驱动
如何识别手写的5。在机器学习的方法中,由机器从收集到的数据中找出规律性。与从零开始想出算法相比,机器学习可以高效的解决问题,节省人力。但是,将图像转换为向量时使用的特征量仍由人设计。为了区分不同的物体,需要设置不同的特征量。
神经网络,直接学习图像本身,连图像中包含的重要特征量也都是由机器来学习的。

训练数据与测试数据
为了追求模型的泛化能力,即解决不存在于训练数据中的数据的能力。因此将数据分为训练数据和测试数据(又叫监督数据)。获得泛化能力是机器学习的最终目标。在处理手写数字的问题上,如果这套算法拥有的泛化能力,他就同样可以用处识别邮政编码,快递单号,等方面。
如果该模型,只能对某个数据集做出正确判断,比如,只能识别某个人的书写,但是无法识别其他的人的书写。这种状态被称为过拟合。避免过度拟合也是机器学习的一个重要课题。