Windows Server 2008 R2 云服务器无法部署opencv python程序的问题
问题:通过各种版本安装anaconda后,安装opencv,提示无法找到.dll文件。 解决办法: 安装windows server 2008的桌面体验功能。 步骤: 以管理员身份登录。 启动服务器管理器。 单击功能。 单击添加功能。 在“选择功能”页面上,选中桌面体验复选框。 查看有关桌面体验功能所需的其他功能的信息,然后单击添加必需的功能。 按…
|
795
|
|
145 字
|
1 分钟内
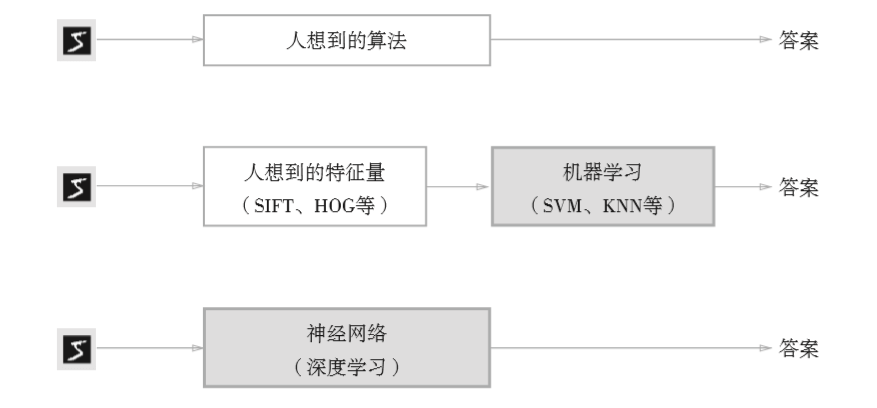
从数据中学习
数据驱动 如何识别手写的5。在机器学习的方法中,由机器从收集到的数据中找出规律性。与从零开始想出算法相比,机器学习可以高效的解决问题,节省人力。但是,将图像转换为向量时使用的特征量仍由人设计。为了区分不同的物体,需要设置不同的特征量。 神经网络,直接学习图像本身,连图像中包含的重要特征量也都是由机器来学习的。 从人工设计规则转变为由机器从数据中学习…
|
942
|
|
402 字
|
2 分钟
神经网络输出层的设计
在分类问题与回归问题的解决上输出层可以采用不同的激活函数!一般来说,回归问题可用恒等函数,分类问题可用softmax函数
|
875
|
|
782 字
|
5 分钟
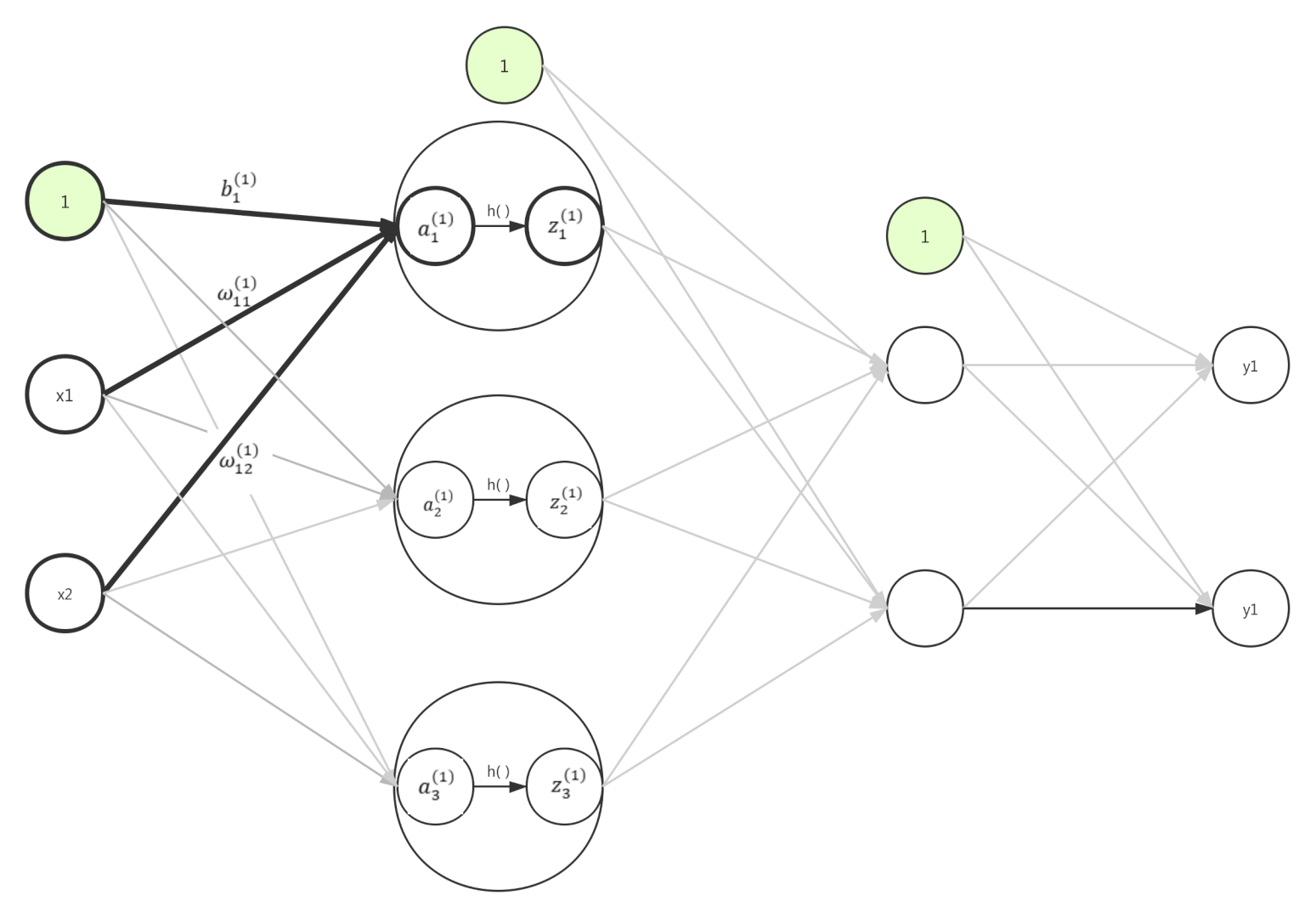
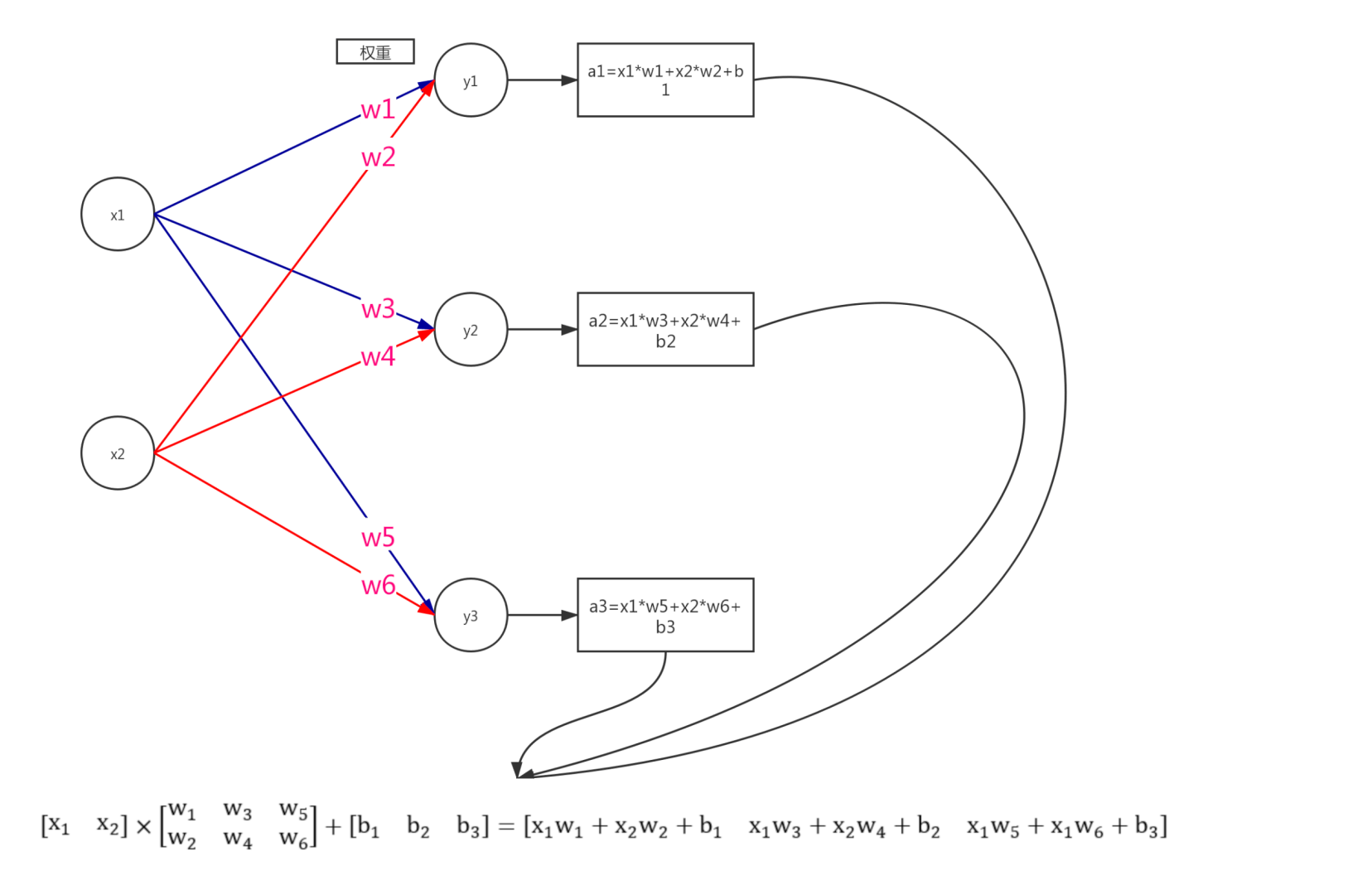
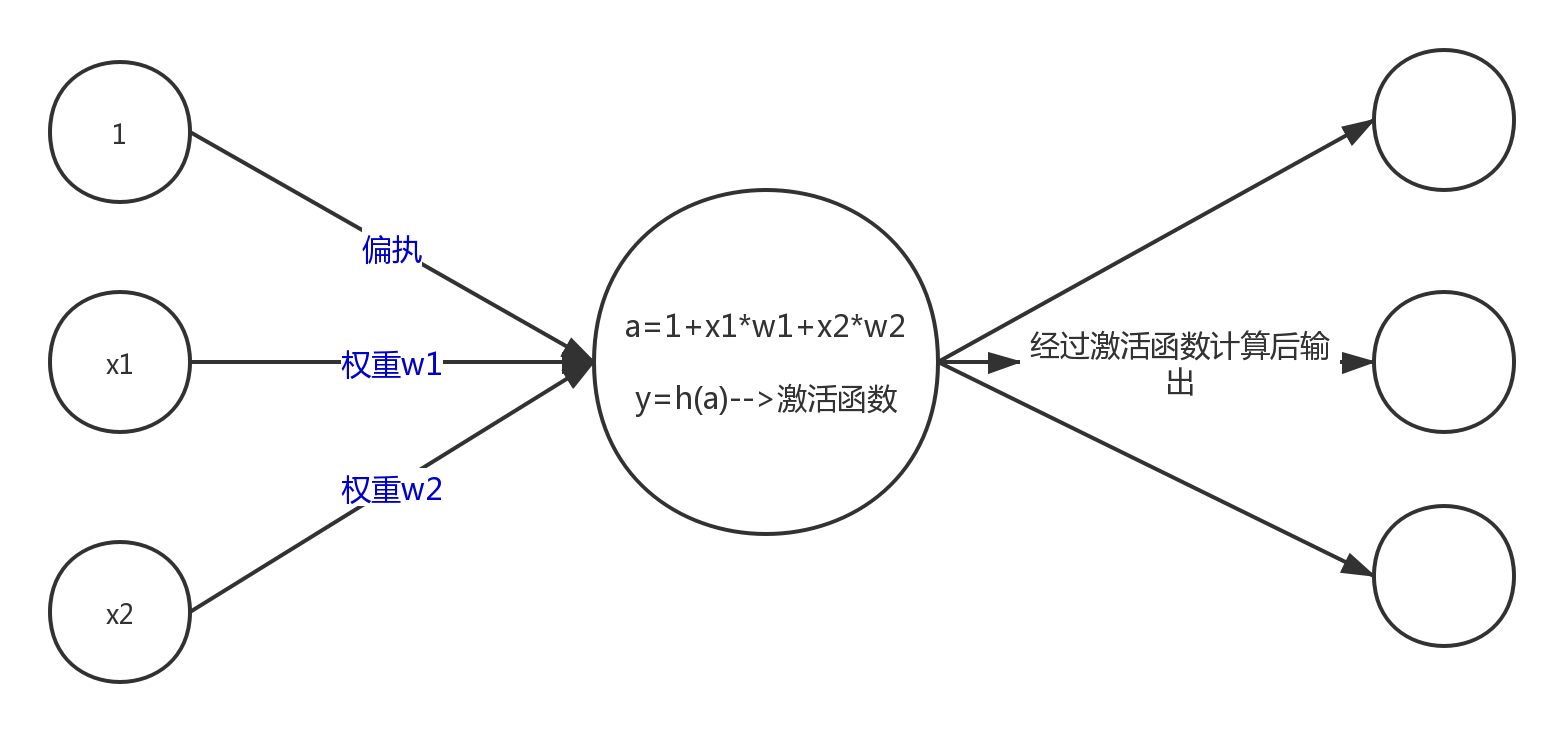
神经网络内积
神经网络数据从一层传递到另外一层,是由多个乘法与加法运算组成,当每一层拥有多个节点的时候,使用矩阵进行内积,会加使得计算更加方便。
|
794
|
|
125 字
|
1 分钟内
从跃迁函数到激活函数
阶跃函数 $f(x) = \begin{cases}0, x \leq 0 \cr 1, x > 0 \end{cases}$ 函数图像 sigmoid函数 $y=\frac{1}{1+e_{}^{-x}}$ 函数图像 由于阶跃函数的输出结果具有跳跃性,且只有0和1这2个输出结果,所以导致了他在向量机中可以表现良好,但是在神经网络的训练中的效果并没…
|
1,230
|
|
173 字
|
1 分钟内
scrapy中多个spider使用多个setting的记录
scrapy中多如何使多个spider使用多个setting的记录
|
620
|
|
73 字
|
几秒读完
django部署到服务器无法访问静态文件的坑
需要在setting中做如下配置: STATIC_URL = '/static/' STATICFILES_DIRS = (os.path.join(BASE_DIR, 'static'),) STATIC_ROOT = os.path.join(BASE_DIR, "static") 然后在项目的主urls.py中加入以下: from touti…
|
952
|
|
53 字
|
几秒读完